讲讲效果
先讲讲从python->go重写项目的最终结论:在高峰期统计总资源使用量,算出重写后的go版相比重写前的python版CPU使用下降了74%,内存使用下降了94%。
不过重写一个项目,在写代码这件事本身结束以后,从检查新代码正确性一直到最后上线还有一段漫长的过程。本文就记录了我们这一段过程的实践。
术语和业务的背景
先介绍背景。我们有一个流量较大的grpc服务,本文暂且给它取代号叫做abc。用python和go实现的版本我们把它叫做abc-py和abc-go。
- abc原本是一个python编写的grpc项目,主要使用了我们的grpc框架sea
- abc实现了数个grpc的servicer,每个servicer都可以对应HTTP/2的一个path。这次我们重写实现了其中一个grpc servicer,对应的path我们把它叫做
/abc.Abc/;没有用go重写的部分的path都统一起来叫做/abc.XXX/ - k8s集群里其他应用请求grpc服务时,都要经envoy做HTTP/2的反向代理
结构图简化如下:
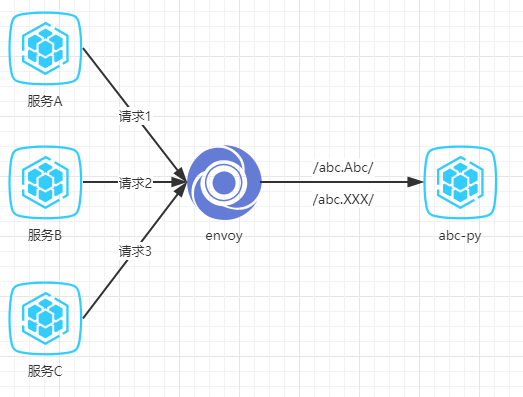
测试的背景
单元测试❎
我们对比着python代码用go重写了项目以后,会照着新代码以及我们理解的业务逻辑来写新的单元测试。
但仅仅使用单元测试是不够的,因为:
- 单元测试能覆盖的场景有限
- 单元测试本质上是白盒测试,重写的单元测试代码和重写的业务代码有一样的问题:
- 会受到已经写过的代码的影响
- 会受到逻辑理解的影响
单元测试没有问题的情况下我们也不能放心让代码上线。
使用abc-py的单元测试代码来测试abc-go❎
理想情况下,如果能直接使用旧代码的单元测试来测新代码,就不会受到新代码和我们理解错误的影响。
但单元测试本身就受到代码的影响,比如python的单元测试里我们使用了框架自带的测试组件、要给对象进行mock等;写go的单元测试前我们就要考虑代码的可测试性,测试这件事对代码本身就是有侵入的。
如果要对原来的单元测试代码进行大量修改,也就必然改动逻辑了。这个方案并不可行。
回归测试
不知道定义上是否准确,但根据维基的解释,重写代码并且保证正确性的这种场景我们需要的是「回归测试」。
黑盒测试❎
首先我们考虑的是一种和单元测试类似的编写方法:同样覆盖所有功能,但以黑盒测试的角度编写代码。然后使用这个黑盒测试代码测试处在同样环境下的abc-py和abc-go的两个服务,不论我们理解的逻辑如何,只要两边结果完全相同,就可以认为验证成功。
但:
- 相比复杂的用户场景,这个方案能覆盖的场景非常有限
- 这样的回归测试方案不能重复使用,我们以后还要迁移很多python项目到go,都要编写只用一次的黑盒测试代码
于是写黑盒测试代码这种方案也不适合我们。
镜像流量✅️
最终我们考虑使用这样的方案:
- 首先代码的单元测试是用于验证逻辑错误
- 其次功能自测和QA的测试能验证功能是否正确
- 最后直接在生产环境部署abc-go服务但并不给用户直接访问,而是把abc-py的流量完全复制一份到abc-go,一段时间后检查每个请求发到abc-py和abc-go得到的响应是否完全一致
其中最重要的是第三步复制流量的方案。
复制流量方案
envoy + diffy❎
由于我们的流量都经过了envoy,使用它的request_mirror_policy可以很容易的镜像每一个请求。
而要分析大量的请求和响应,我们找到了diffy这个工具。它一开始由twitter维护、目前由opendiffy这个GitHub组织维护。
他的功能是可以把一个HTTP请求发往两个地方,并且比较和统计他们的输出;在对比结果里也可以方便的选择忽略一部分请求、忽略某个字段、忽略一定百分比内的内容不一致等等,还是比较强大。
然而它并不支持解析对比grpc的流量,所以我们只能修改了一个提供http接口、功能和abc-py相同的项目(这里把它叫做abc-api),把他自己的逻辑去掉,改为调用abc-go的grpc接口。然后做了镜像流量,最终结构如下:
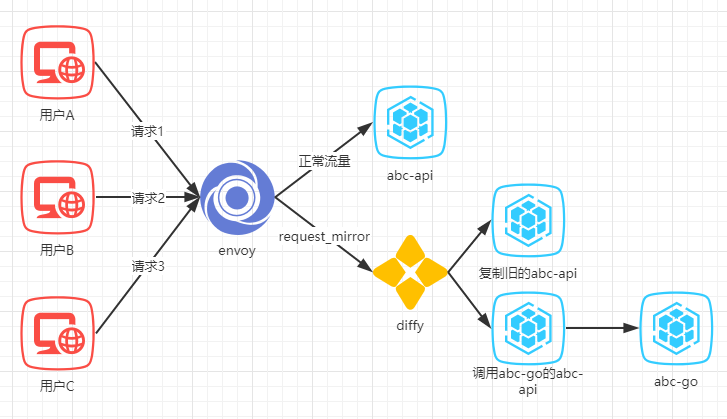
看到结构图以后可以发现,这样的方案明显非常不合理,而我们仅仅是为了用上diffy这个现成的工具就引入了更复杂更不可控的环节:
- 我们又修改了一个项目的代码逻辑(abc-api)
- envoy复制了一份流量之后diffy又会复制一份,现在abc-api项目的流量*3
- 我们仅仅因为abc-api和abc-py功能类似就认为两者逻辑等效,实际上并非如此,我们应该只对比abc-py和abc-go
- 由于有非幂等的请求,我们必须让三份流量的非幂等逻辑各自独立。主要就是写数据库的部分,abc-api/复制的abc-api/调用abc-go的abc-api三者各自连接了独立的数据库。并且在上线前我们要保证三者完全同步,然后在上线diffy的同时关掉同步。
于是乎结果就是diffy看到了大量的不一致,但我们无法直接判断不一致是abc-go的问题还是我们修改abc-api引入的新问题。这个方案不可行。
envoy + 对比grpc响应✅️
吸取了上面的经验之后,我们明白请求过程的结构越简单、代码改动越少越好。而对比响应内容带来的复杂性应该被放到这个结构以外,甚至可以离线来做。最终,我们选择使用envoy镜像grpc流量:
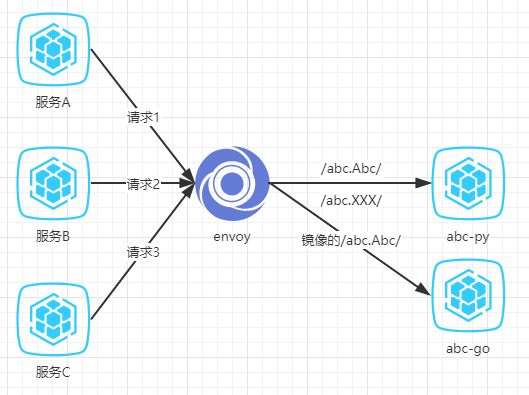
- 我们配置了envoy的路由,当path为/abc.Abc/时,请求照旧发到abc-py,但是会镜像一份流量到新部署的abc-go服务
- abc-py和abc-go连接着各自独立的数据库,在镜像流量前两个数据库保持同步
- 我们编写了python和go版本的middleware,用来给输入输入以及req_id等数据进行打点。打点数据将会被收集到我们的elasticsearch
这个方案在结构上,相比一开始只多出一份abc-go的服务;在代码上,相比一开始只多了一个打点的middleware。
对比响应的方式则是我们定时从elasticsearch拉数据,编写了一个脚本用来对比数据中同一个req_id的两次请求结果是否一致。这个脚本用到了dictdiffer这个库,功能只是对比响应内容是否一致以及忽略字段等,和业逻辑无关,所以其他业务做回归测试时一样可以使用。
这样「镜像流量->对比结果->修复代码」过程反复多次以后,我们最终能做到一段时间内每个请求abc-py和abc-go都有完全一样的响应。
灰度上线
上面的步骤都做完,做到abc-go和abc-py响应完全一致以后,我们还是不能直接替换。为了避免没有想到的情况发生,我们必须灰度上线。
不过这次灰度上线比以往复杂一些,并不能直接用abc-go一个一个替换abc-py。为了解释更清楚,需要先介绍下之前的envoy配置的路由方案,大致可以简化为(实际上envoy并不像下图一样直接调用k8s的service):
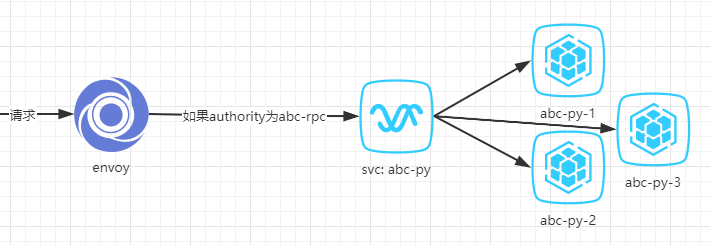
- 请求进来时,如果请求头的authority为abc-rpc,根据我们的配置,envoy会取到k8s里名为abc-py的这个service对应的pod ip,随机发往其中一个。
而我们的abc-go只实现了所有authority为abc-rpc的请求里path为/abc.Abc/的这一部分,如果直接用abc-go替换abc-py会有一些请求未实现。
因此我们的灰度要分为两个步骤来做:
- 一:创建新的svc,让
/abc.Abc/的请求走到这个新的svc。新svc对应的pod依然是abc-py - 二:一个一个替换掉它们为abc-go
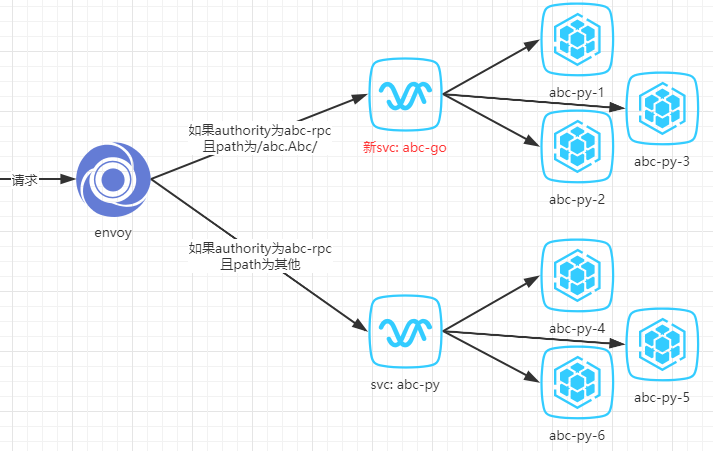
上图就是步骤一完成之后的效果。此时所有的请求都没有受到影响,因为并没有abc-go的代码上线。这时我们只要一个一个替换掉abc-py-1/2/3为abc-go的代码,就能实现灰度上线。
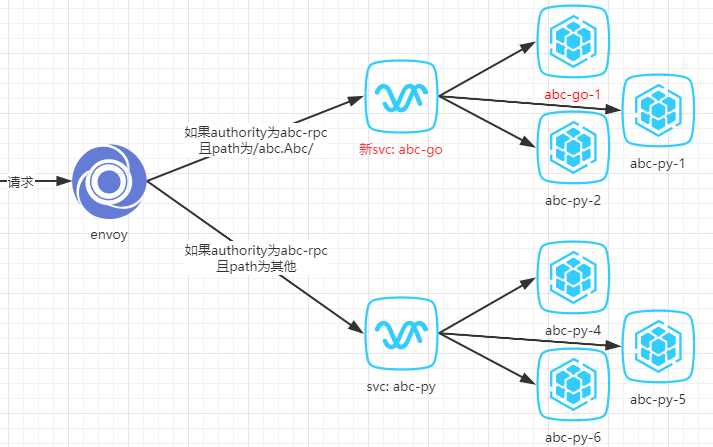
最终新svc背后的pod都替换成abc-go的代码,项目上线成功。